ESMM: Entire Space Multi-Task Model: An Effective Approach for Estimating Post-Click Conversion Rate
ESMM et al. - Part 2
This post is about the first paper which introduces the ESMM approach. The full paper is available here, it is fairly easy to read.
Which Issues ESMM Addresses?
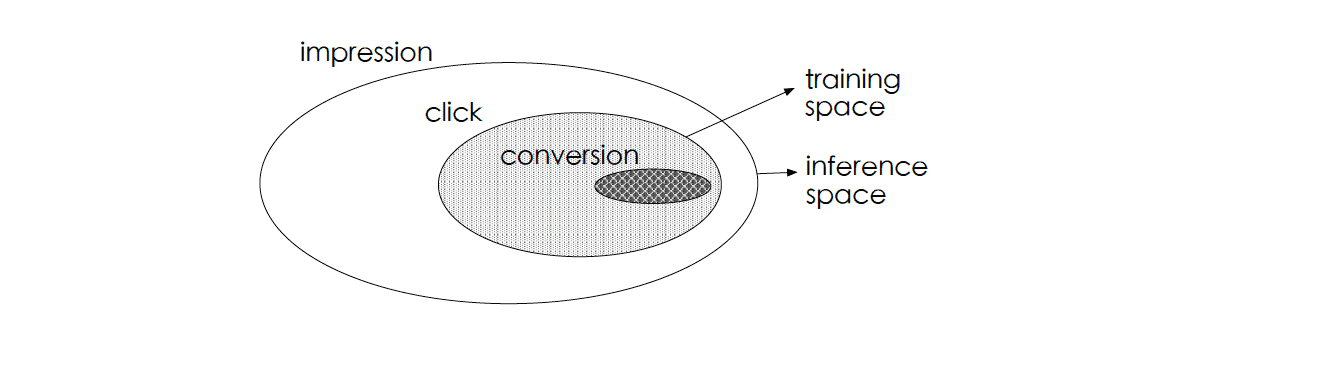
ESMM proposes an approach to address sample selection bias (SSB) and data sparsity (DS) associated with CVR models. These problems arise due to difference in training vs inference space (SSB) and difficulty in fitting the CVR model due to sparsity of training data (DS) respectively.
The paper does not focus on the delayed feedback problem of CVR because they mention that it is somewhat acceptable in their case. This means that the time delay between click to conversion is within an acceptable time window and does not lead to data staleness issue in the model training process.
ESMM Approach
Intuition/Explanation
ESMM authors assume that user actions follow the sequential pattern,
impression => click => conversion
This can be expressed in probability as,
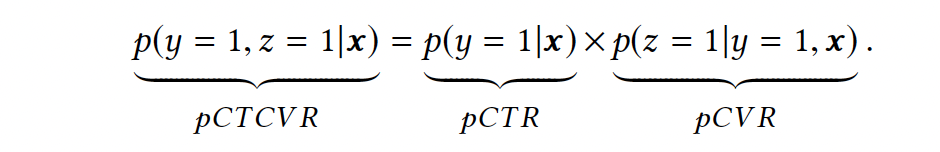
where x is the feature vector of observed impression, y is click label and z is conversion label.
A baseline (naive) approach to train CVR model is to take all the clicked samples and further treat converted cases as positives and clicked but not converted cases as negative. Clearly, this dataset is a subset of all impressions on which inference needs to be done (as is evident from the equation above also). Therefore, the naive approach suffers from the SSB issue. However, CTR and CTCVR can be trained directly on the impression data as there is no other conditioning variable. This fact is used to design the ESMM approach.
SSB: In ESMM, two auxiliary tasks of predicting the post-view CTR and post-view CTCVR are introduced. ESMM treats pCVR as an intermediate variable which multiplied by pCTR equals to pCTCVR.
Both pCTCVR and pCTR are estimated over the entire space with samples of all impressions, thus the derived pCVR should also be applicable over the entire space.
DS: To address DS of CVR task, embedding table is shared with CTR task. This leads to training of parameters over samples of all impressions, i.e. the entire space.
Proposed Architecture
The architecture below is fairly self-explanatory at a high level.
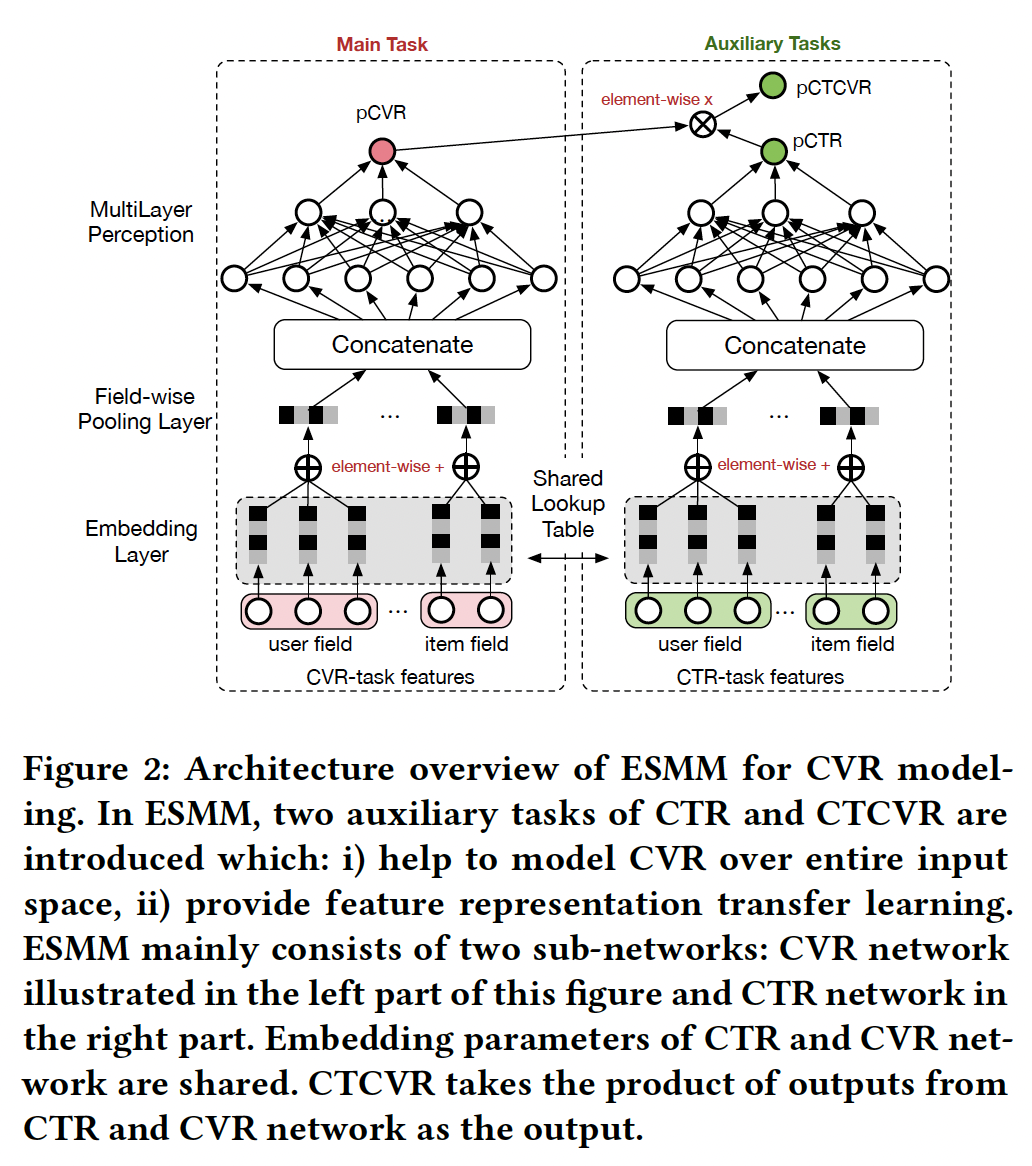
Details of architecture:
pooling over user and item field embeddings
ReLU activation function
dimension of embedding vector is 18
each layers in MLP network is 360 x 200 x 80 x 2
adam with parameter β1 = 0.9, β2 = 0.999
ϵ = 10−8
Loss
Notice that
total loss is a sum of of losses for CTR and CTCVR tasks
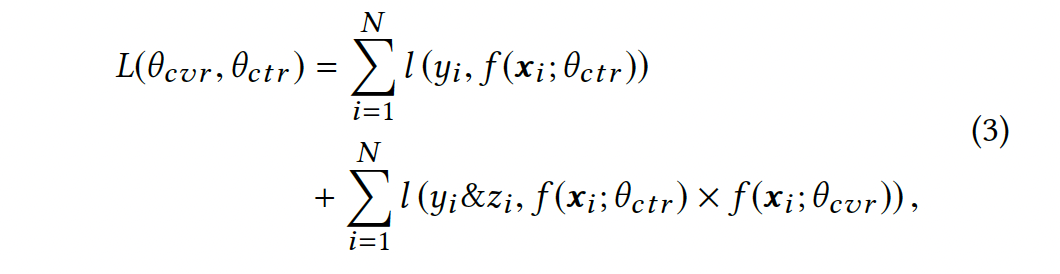
since the training tasks are defined over the entire space, therefore naturally the corresponding losses are also defined over the impression space.
Results Discussion
Baselines
Baseline approaches used in the paper for comparison are:
Base: CVR model trained in click space with architecture similar to CVR task in the proposed architecture section above.
AMAN: All Missing As Negatives, "applies random sampling strategy to select unclicked impressions as negative examples".
OVERSAMPLING: "copies positive examples to reduce difficulty of training with sparse data".
UNBIAS: "fit the truly underlying distribution from observations via rejection sampling. pCTR is taken as the rejection probability."
DIVISION: estimates pCTR and pCTCVR with individually trained CTR and CTCVR networks and calculates pCVR by pCVR = pCTCVR/pCTR.
ESMM-NS: ESMM with No embedding parameter Sharing
Offline Results
Results are reported on public dataset which was released as part of this publication and the whole dataset called as product dataset.
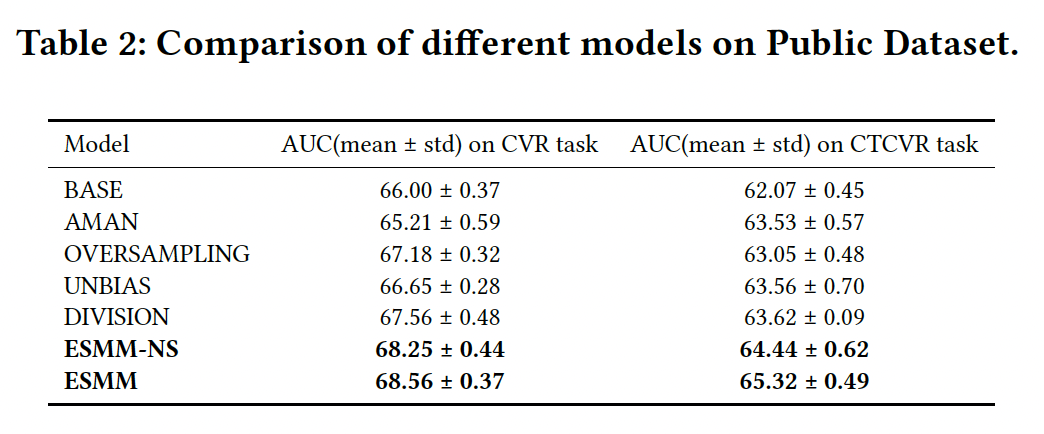
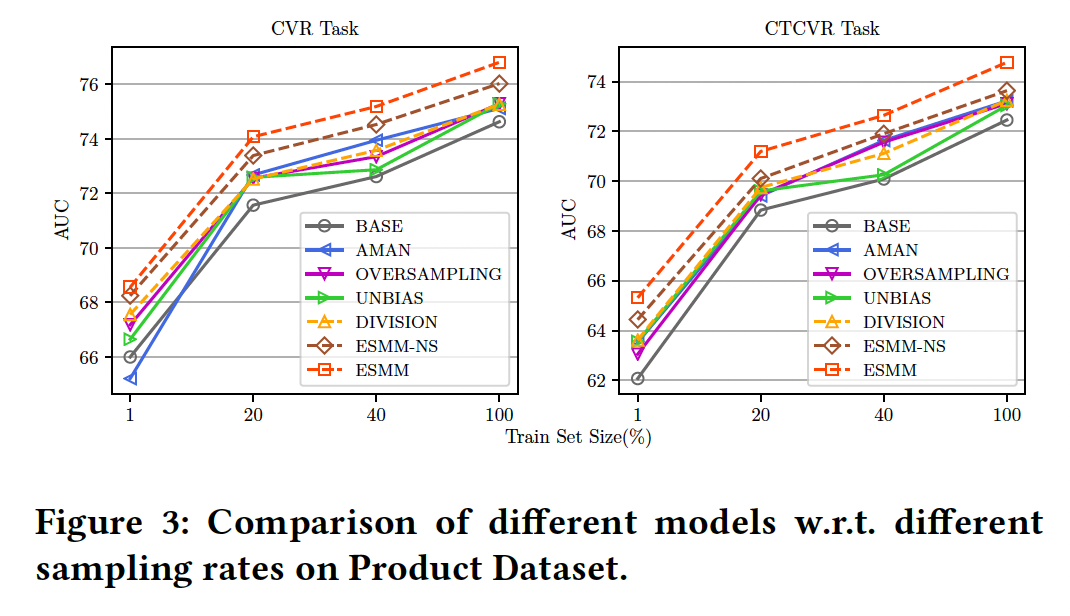
The results show that ESMM performs better compared to other baselines.
Observations/Thoughts/Questions
The odd thing about the approach is that, the main task (CVR) which ESMM is trying to get better at is just an intermediate variable with no direct supervision on it. Therefore, is it possible that the intermediate variable is optimised properly?
Embedding dimension is just 18 (maybe in 2018 it was still hard to train larger models?)
The paper does not mention that this model is deployed in production, all results reported are offline.
They do not describe whether CTCVR task improved the CTR task performance. Should it?
One of the baseline methods is All Missing As Negative (AMAN) which consistently underestimates prediction mentioned in the literature section of the paper, and it also performs worse among ESMM baselines.
Another competitor models in result section is ESMM-NS, i.e. ESMM without embedding parameter sharing and its results are only marginally worse than ESMM with parameter sharing. Does it mean that DS is only partially addressed?