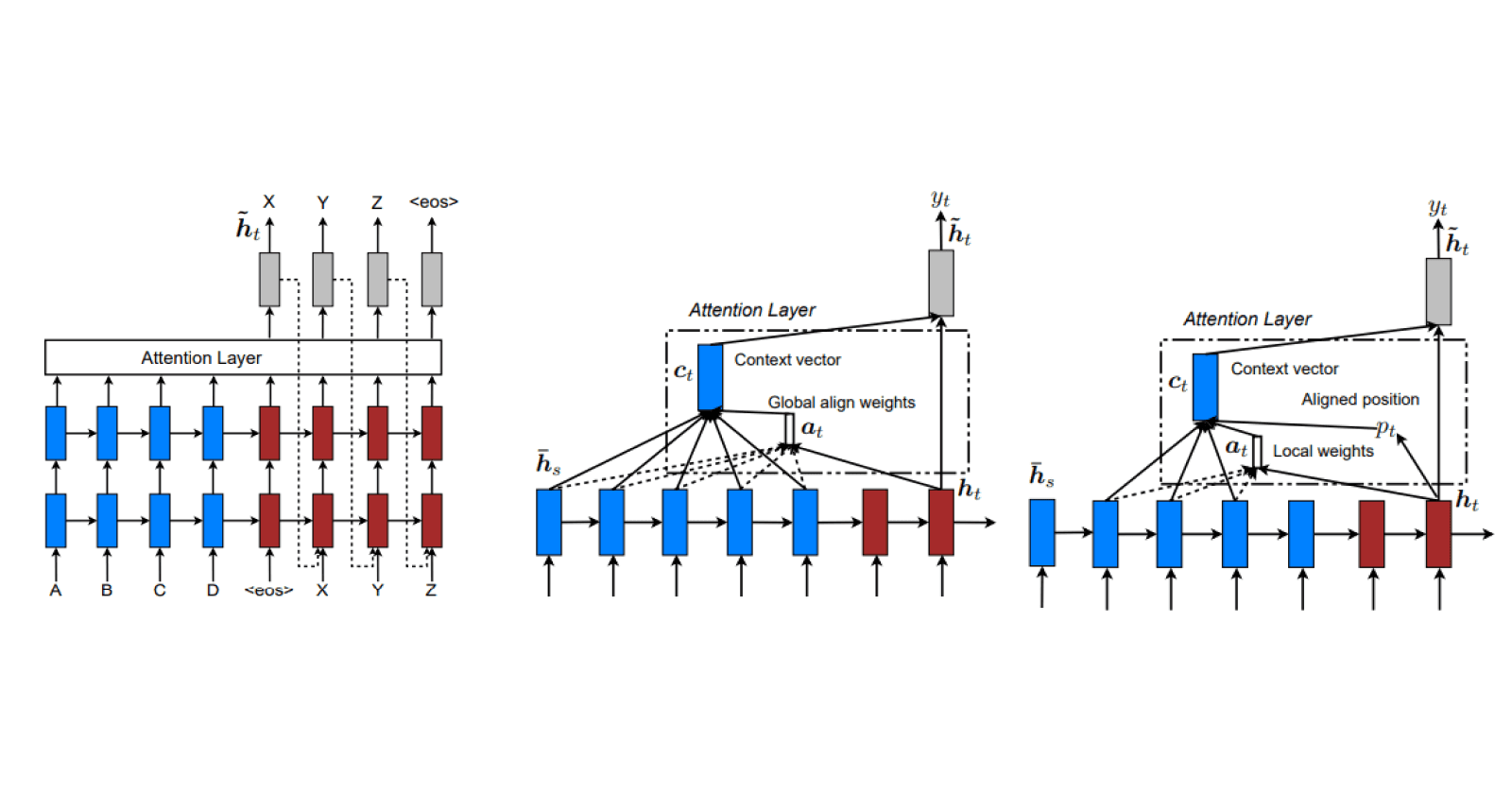
Hard, Soft and Doubly Stochastic Attention

For the image captioning task, the paper Show, Attend and Tell: Neural Image Caption Generation with Visual Attention proposes three different attention mechanisms,
Stochastic Hard Attention
Deterministic Soft Attention
Doubly Stochastic Attention (variation of Deterministic Soft Attention)
The proposed architecture for image captioning has a CNN encoder to extract feature maps from the image and LSTM decoder to predict the tokens of the caption.

The common steps in all three attention mechanisms is as follow,
- CNN is used to extract L feature vectors, called annotation vectors in the paper, from the image
$$a = \{\mathbf{a}_1,..., \mathbf{a}_L\}, \mathbf{a}_i \in \mathbb{R}^D$$
- For previous hidden state of the decoder \(h_{t-1}\) and each annotation vector \(a_i\), attention weight/score \(\alpha_{t, i}\) is calculated as,
$$\begin{align} e_{t,i} &= MLP(\mathbf{a}_i, \mathbf{h}_{t-1}) \\ \alpha_{t,i} &= \frac{exp(e_{t,i})}{\sum_{k=1}^{L}exp(e_{t,k})} \\ \end{align}$$
\(\alpha_i\) can be interpreted either as the probability that location i is the right place to focus for producing the next word, or as the relative importance to give to location i in blending the \(a_i\)’s together.
Stochastic Hard Attention
At step t, \(\alpha_{t,i}\)’s are used to define a multinoulli distribution,
$$s_{t,i} = Multinoulli(\{\alpha_{t, i}\})$$
\(s_{t,i}\), thus, is an indicator one-hot variable which is set to 1 if the i-th location (out of L) is the one used to extract visual features.
The attention vector is then computed as,
$$\hat{\mathbf{z}}_t = \sum_{i=1}^{L} s_{t,i}\mathbf{a}_i$$
Essentially in this case you sample from the multinoulli distribution and the feature vector corresponding to the selected index (location) becomes the attention vector.
Deterministic Soft Attention
Deterministic Soft Attention mechanism computes expected attention vector using the attention weights as
$$\hat{\mathbf{z}}_t = \sum_{i=1}^{L} \alpha_{t,i}\mathbf{a}_i$$
The authors also use a gating scalar \(\beta\) (predicted from previous hidden state of decoder) for the attention vector, i.e.
$$\begin{align} \beta_t &= \sigma(MLP(\mathbf{h}_{t-1})) \\ \tilde{\mathbf{z}}_t &= \beta_t\sum_{i=1}^{L} \alpha_{t,i}\mathbf{a}_i \end{align}$$
Authors observe that the attention weights put more emphasis on the objects in the images by including the scalar \(\beta\).
Doubly Stochastic Attention
Doubly Stochastic Attention modifies Deterministic Soft Attention by introducing a form of doubly stochastic regularization by encouraging \(\sum_t{\alpha_{t, i}} \approx 1\). This can be interpreted as encouraging the model to pay equal attention to every part of the image over the course of generation.
Doubly stochastic regularization is achieved by adding the regularization term as,
$$L = -\log(P(\mathbf{y}|\mathbf{x})) + \lambda\sum_{i}^{L}(1 - \sum_{t}^{C}\alpha_{t, i})^2$$
where C is the length of target.