ESM2: Entire Space Multi-Task Modeling via Post-Click Behavior Decomposition for Conversion Rate Prediction
ESMM et al. - Part 3
In this post I summarise the ideas in the paper "Entire Space Multi-Task Modeling via Post-Click Behavior Decomposition for Conversion Rate Prediction". You can find the paper here.
Recap
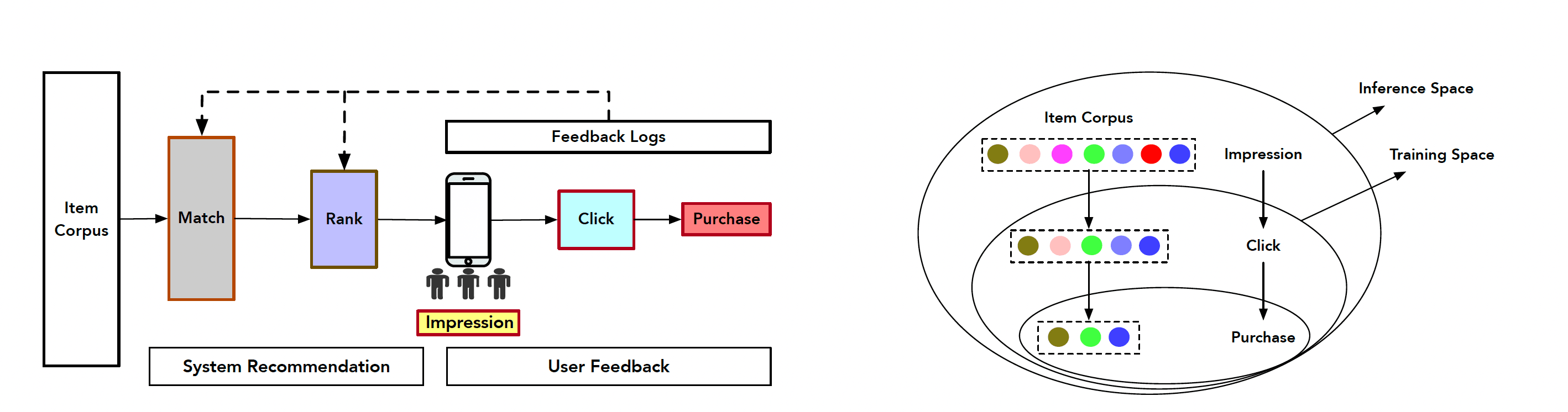
A quick recap of the previous paper discussed in the previous post: ESMM attempts to address the Sample Selection Bias (SSB) and Data Sparsity (DS) challenges associated with CVR modelling. SSB is solved by training the model in the entire space through CTR (P[click = 1 | impression]) and CTCVR (P[order=1 and click = 1 | impression]) tasks. Since these two tasks are defined on the entire impression space, the derived pCVR = pCTCVR/pCTR is also valid in the entire space.
DS is solved by sharing the embedding parameters between CTR and CVR tasks, which otherwise will not be properly trained just for CVR task due to lack of enough supervision (conversion events are rare).
With this context, let's look at the model Elaborated Entire Space Supervised Multi-task Model (ESM2) proposed in the current paper.
Motivation Behind ESM2
Authors point out that purchase events are rare (only 1% CVR and 0.1% CTCVR in online real-world logs), as a result existing methods still struggle to address the DS issues in CVR modelling. In the context of the ESMM paper, I think this means that while the CTCVR task helps, it still does not provide enough supervision to address the DS issue.
How can we provide more supervision?
Users take several actions post-click, such as add-to-cart, wishlist, another item click etc, before they make a purchase. Maybe they add items relevant to them in their wishlist and wait for discounts. Or they add all the relevant items to the wishlist or cart as shortlists but do not want to make a purchase decision immediately. Many of these post-click actions are related to eventual purchase. If these actions are leveraged then they can potentially provide abundant supervision signals to train the CVR model, compared to purchase signals alone.
With these additional supervision signals along with the ideas proposed in ESMM, not only can CVR be modelled in the entire space but data sparsity issues can also be further alleviated. This is the core idea behind ESM2.
Approach
User Sequential Behaviour Graph: Types of Post-Click Actions
To make things simple, different types of post-click actions in the user browsing behaviour graph can be grouped into Deterministic Action (DAction) for purchase and Other Action (OAction). In the figure below, it is shown that 12% of add-to-cart and 31% of wishlist items lead to purchase respectively in the data analysed by the authors. Such high intent post-click actions are grouped into DActions and other low intent post-click actions are grouped into OAction.
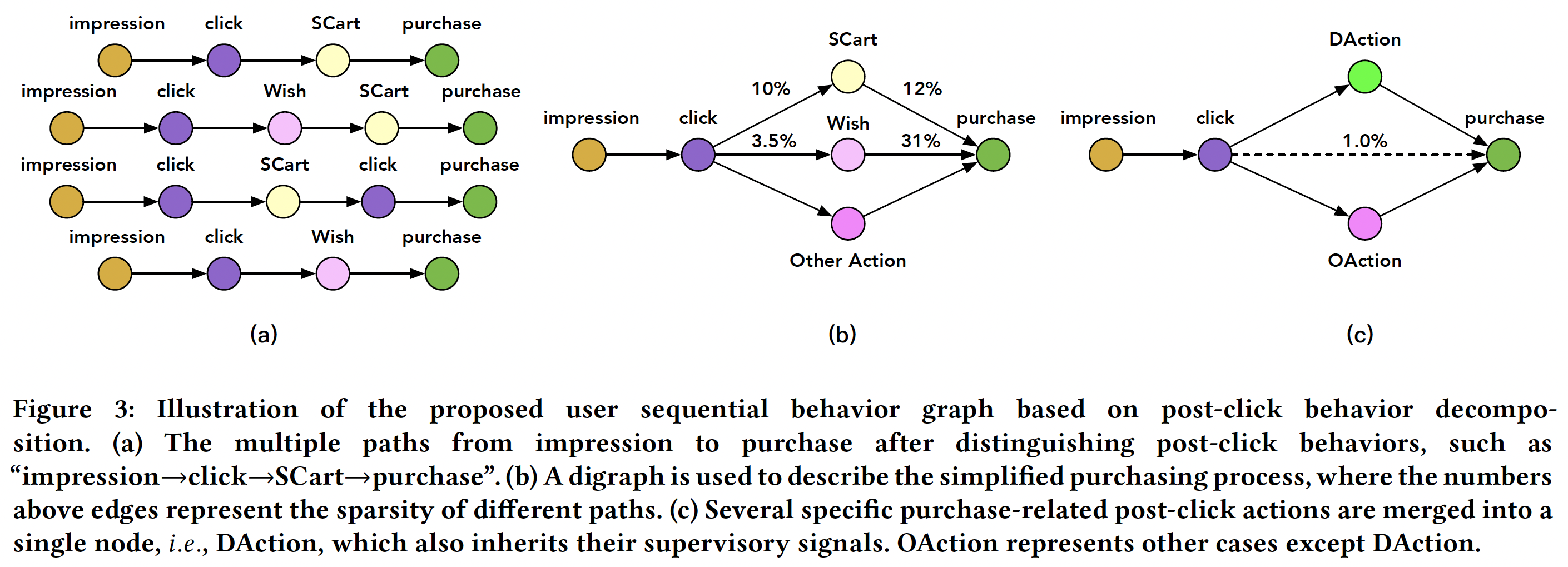
Probabilistic Formulation of User Sequential Behaviour Graph
The terminology for labels and conditioning variables followed in the paper is as follows:
v = view
c = click
a = action (1 means DAction, 0 means OAction)
b = purchase
Based on the graph (c) in the figure above, let's define probability on different segments of the graph
impression => click
$$y1 = p(c = 1 | v = 1)$$
click => DAction
$$y2 = p(a = 1 | c = 1)$$
click => OAction
$$1 - y2 = p(a = 0 | c = 1)$$
DAction => purchase
$$y3 = p(b = 1 | a = 1)$$
OAction => purchase
$$y4 = p(b = 1 | a = 0)$$
Now we can define different quantities of interest for modelling,
impression => click
$$pCTR = y1$$
impression => click => DAction
$$pAVR = y1*y2$$
click => D(O)Action => purchase
$$pCVR = y2*y3 + (1 - y2)*y4$$
impression => click => D(O)Action => purchase
$$pCTCVR = pCTRpCVR = y1(y2*y3 + (1 - y2)*y4)$$
You can also visualize these probability calculations in the tree below,
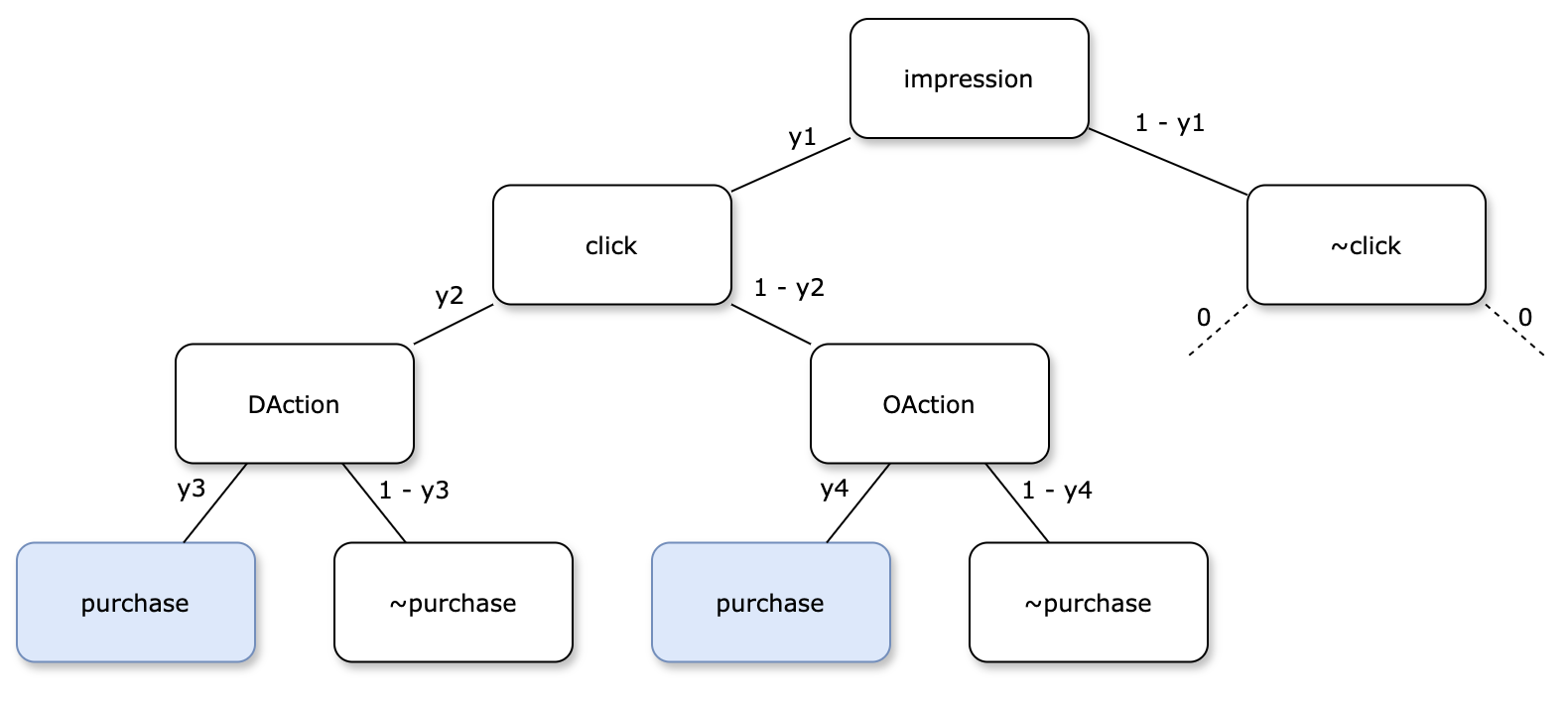
In ESM2, CVR modelling is done leveraging these relationships in user sequential behaviour graph.
Proposed Architecture
The architecture proposed by the authors follows the ideas in ESMM where supervision is provided for impression space labels and other variables are treated as intermediaries. As a result, CTR (impression => click), CTAVR (impression => click => DAction) and CTCVR (impression => click => D(O)Action) => purchase) are the three tasks on which ESM2 model is trained. The architecture is shown in the figure below.
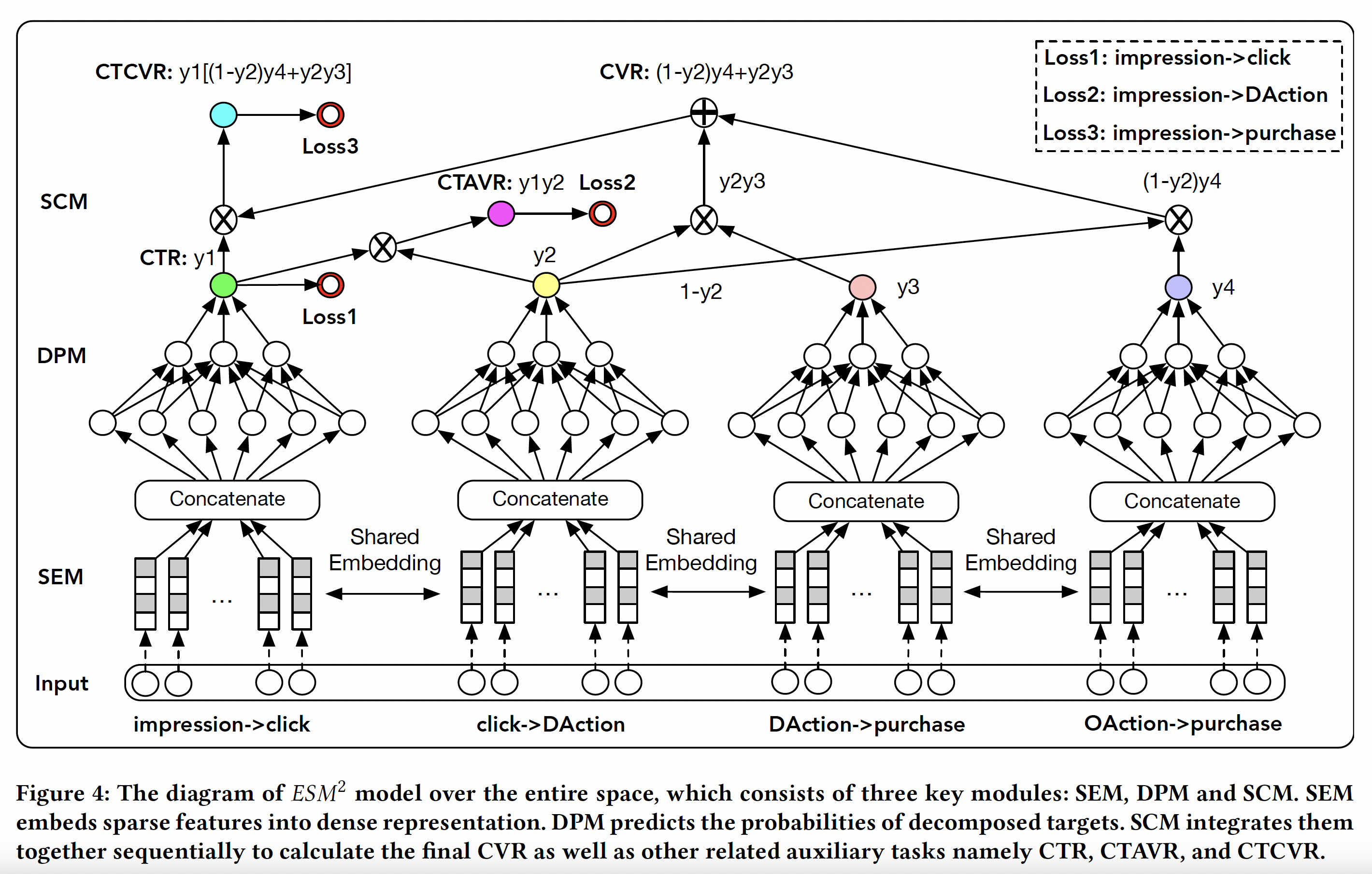
There are three modules in the architecture,
SEM: Shared Embedding Module is shared across tasks and addresses the data sparsity.
DPM: Decomposed Prediction Module has MLPs trained separately for specific tasks and intermediary variables.
SCM: Sequential Composition Module enforces the sequential relationships defined in the user sequential behaviour graph.
Loss
The overall loss for the model is,
$$L(\Theta) = w_{ctr} \times L_{ctr} + w_{ctavr} \times L_{ctavr} + w_{ctcvr} \times L_{ctcvr}$$
where each individual loss L is the logloss for the respective task and w indicates the weight associated with the corresponding loss.
Evaluation Metric
AUC, GAUC and F1 score are used for model evaluation.
Features
The user features include users' ID, ages, genders and purchasing powers, etc.
The item features include items' ID, prices, accumulated CTR and CVR from historical logs, etc.
The user-item features include users’ historical preference scores on items, etc.
Dense numerical features are first discretized based on their boundary values and then represented as one-hot vectors. For numerical features, they alternatively also try tanh transformation and found marginal improvement in AUC.
$$g_{ij} = tanh \Bigg(\cfrac{f_{ij} - \mu_{f_{j}}}{\sigma_{f_{j}}}\Bigg)$$
Result Discussion
Baselines
GBDT: gradient boosting decision tree model
DNN: similar to a single branch of ESM2
DNN-OS: similar to DNN with label oversampling to address DS
ESMM: which models impression=>click=>purchase with any other post-click action
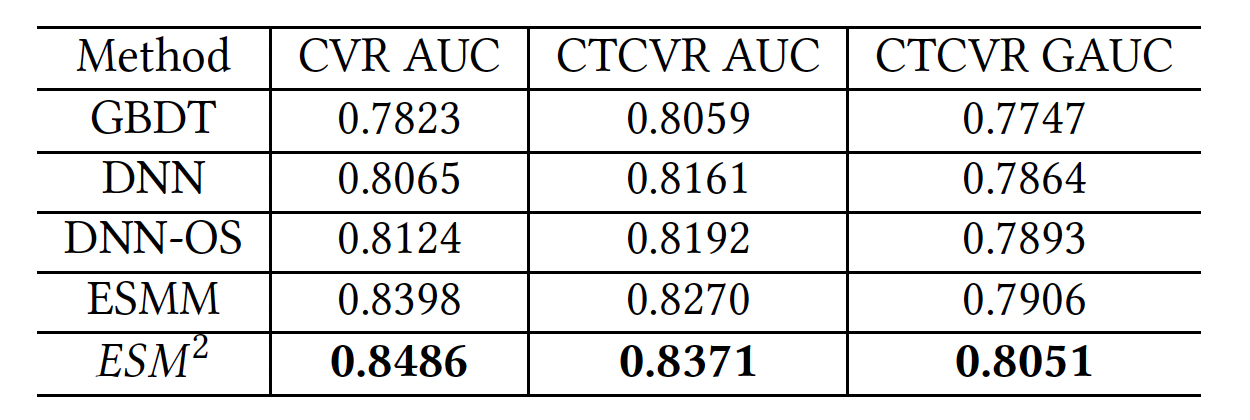
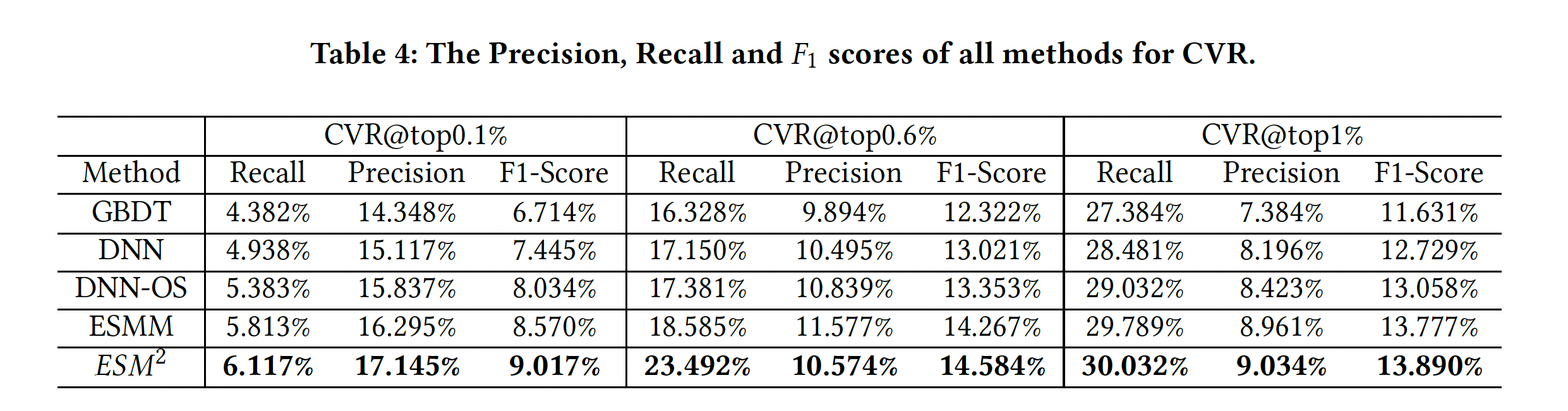
Offline Results
Offline results show that ESM2 outperforms all other baselines.
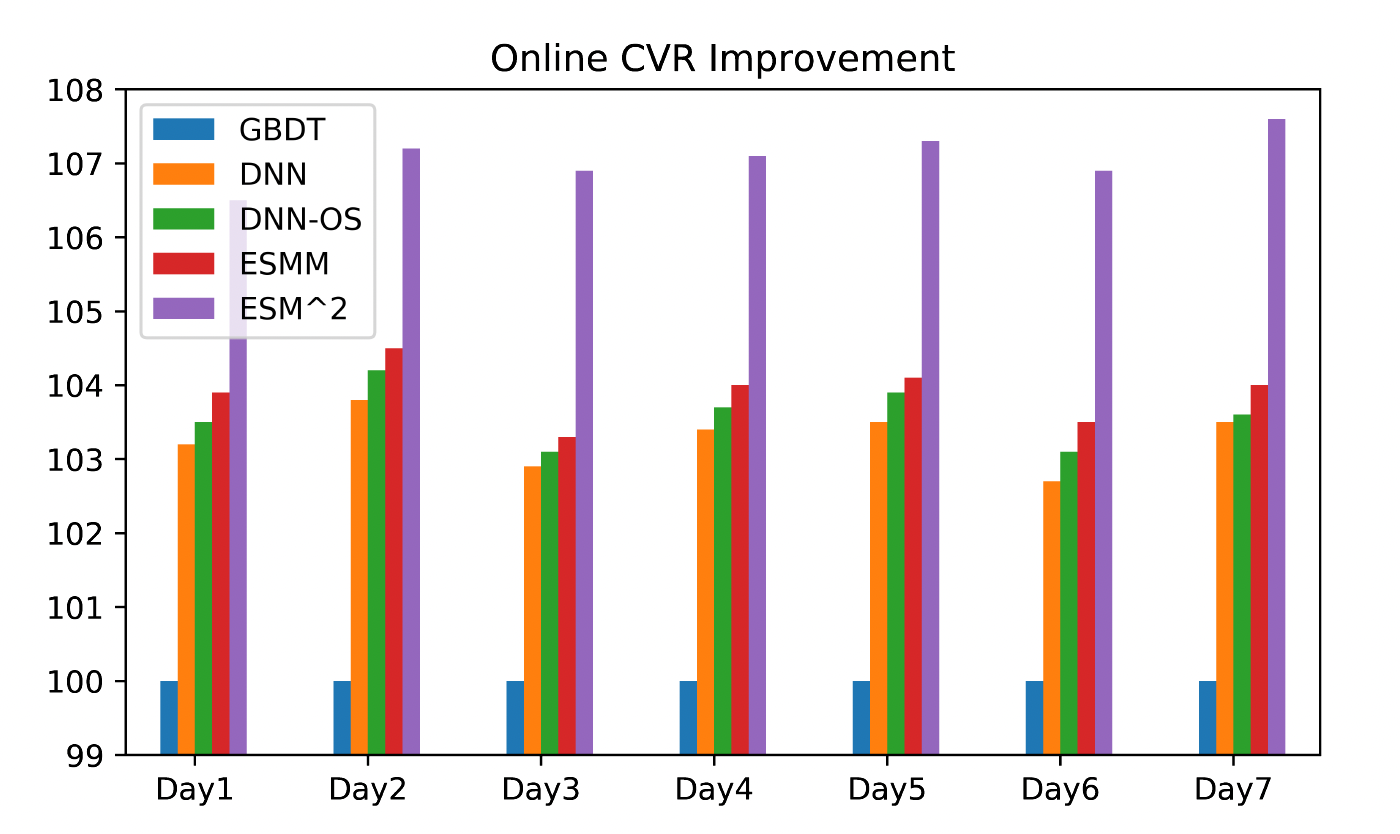
Online Results
Online results validates the offline performance and show that ESM2 outperforms other baselines and has significant improvement over ESMM.
Questions/Observations
What is enforcing the model to train intermediate variables y2, y3 and y4 to train properly?
What might be the intuition
tanhworked slightly better for numerical features instead of discretized embedding based approach?The approach shows significant improvement over ESMM, does it mean the issues with CVR training with ESMM are resolved with this approach?
IDs are used as inputs in the model on which embeddings are learned
The model was deployed online, model latency is 20 ms.