An Introduction to Entire Space Multi-Task Modeling
ESMM et al. - Part 1
In this post, I will use ESMM et al. to describe ESMM and subsequent research along this line of work. I will only motivate/introduce the need for ESMM et al. in the post below.
ESMM et al. aims at addressing the issues with modeling conversion (CVR) such as data sparsity, sample selection bias and delayed feedback issue. In general, I think, these ideas are applicable to many other post-conversion events/feedback such as rating and re-order. But for simplicity, you can think of CVR for reference.
What are the issues with CVR Modeling (P[Order | Click, X])?
Sample Selection Bias (SSB)
"SSB refers to the systematic difference of data distributions between training space and inference space." The figure below from ESMM [2018] paper captures the essence of SSB.
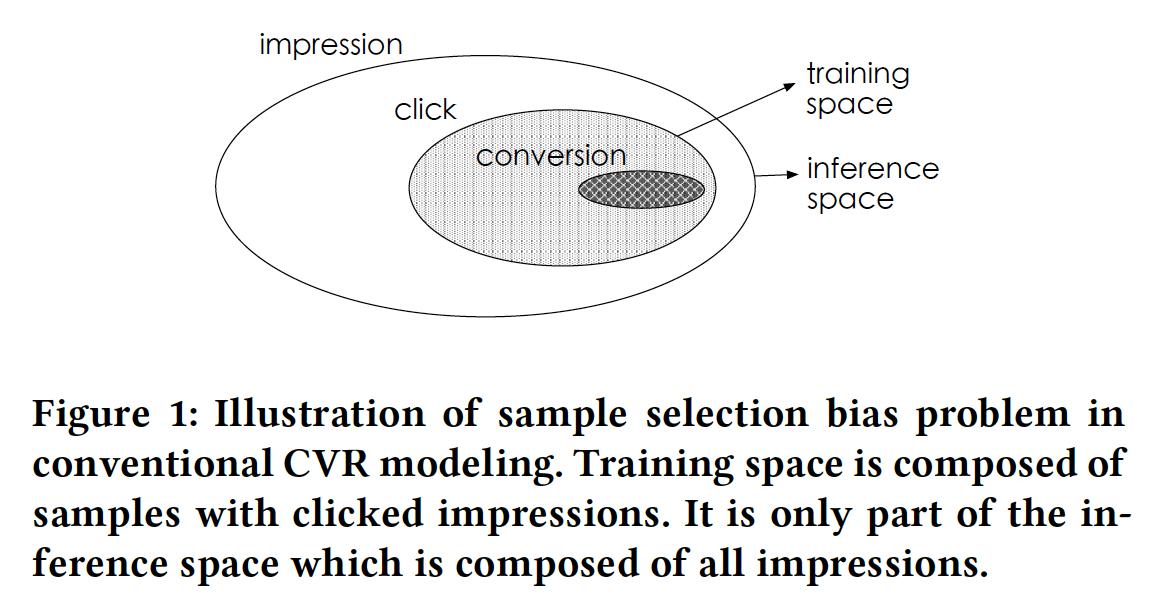
SSB: Entire Space Multi-Task Model: An Effective Approach for Estimating Post-Click Conversion Rate
So the issue with CVR is that the model is trained on clicked samples but the inference is done in impression space (this is not completely true though, can you think why?). This bias is quite severe considering that CTR is typically in the range 3-4%, which means a very small subset of items on the platform get clicked and a subset of them are used for CVR training. But during inference this set is extended to the entire impression space.
As you can guess, this hurts the generalization capability of the model.
Let's come to the second issue.
Data Sparsity (DS)
DS simply means not having enough supervision data to train a model with a large number of parameters. As pointed out earlier, this will happen because CTR is about 3-4% and even if CVR is 10%, if the model has a lot of parameters the CVR data might not be enough to reasonably train the model, leading to underfitting and generalization issues.
The third issue is,
Cascade Delayed Feedback (CDF)
Delayed Feedback (DF) is the issue where the conversion label is not available soon after a click event occurs. E.g. It's quite common in the ads industry to have an attribution window of 30 days or so for conversion post clicking an ad. This means that when you are training a model, your training data will always have a significant staleness w.r.t. to production data distribution.
CDF is the case where the delayed feedback labels have a cascading effect. E.g. returns can only happen after conversion. So the delay in conversion will have a cascading effect on returns feedback. This means when modeling net conversions, the staleness in training data w.r.t. production will be even more.
These are the three major issues ESMM et al. attempts to address.
Now to conclude this introductory post...
What's in the name ESMM?
ESMM name is composed of two things:
ES i.e. Entire Space: where the idea is to train the CVR model in the entire space in which inference is to be done.
MM i.e. Multi-task Model: which hints at the architecture that multi-task modeling is to be leveraged for the entire space training to address SSB and also to solve DS issues.
PS: For folks who are aware of ESMM et al., please do add in comments anything I missed to motivate ESMM.