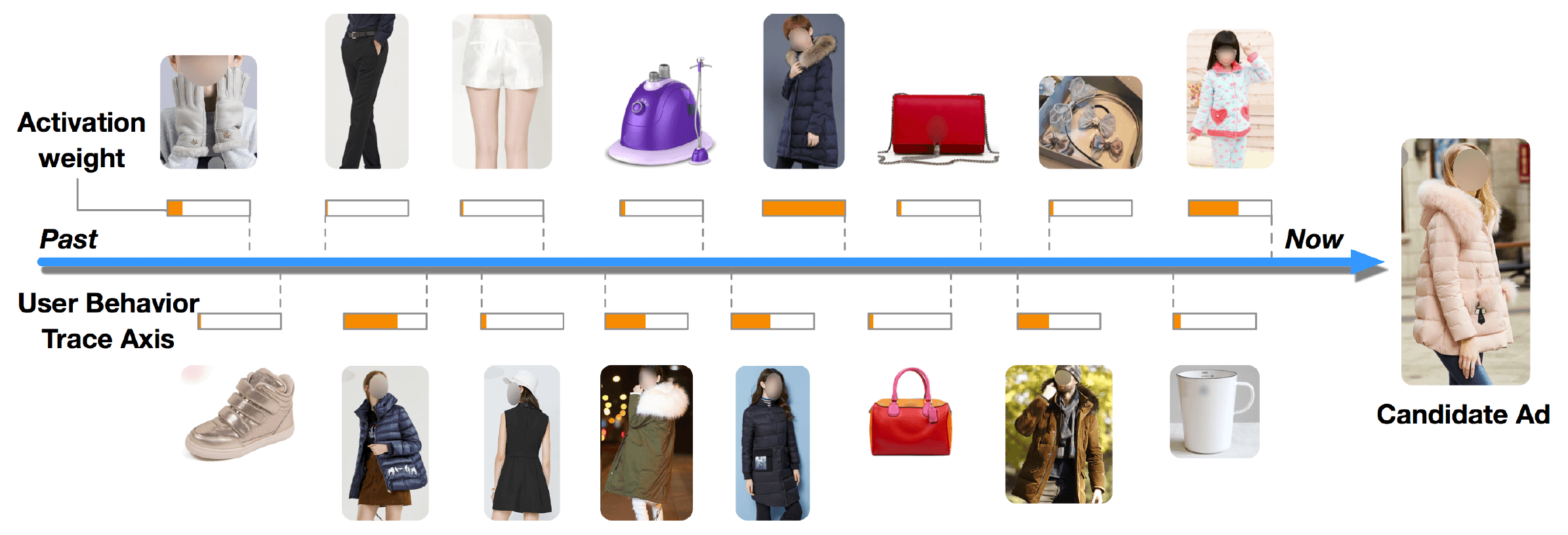
Bahdanau Attention
The paper Neural Machine Translation by Jointly Learning to Align and Translate formally introduced the concept of attention for the first time.
One of the illustrations (shown below) presented in the paper Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation is quite interesting in this context.

What if context vector C is computed by taking all the hidden states of the encoder?
What if context vector C is computed for each decoding step differently?
Bahdanau Attention
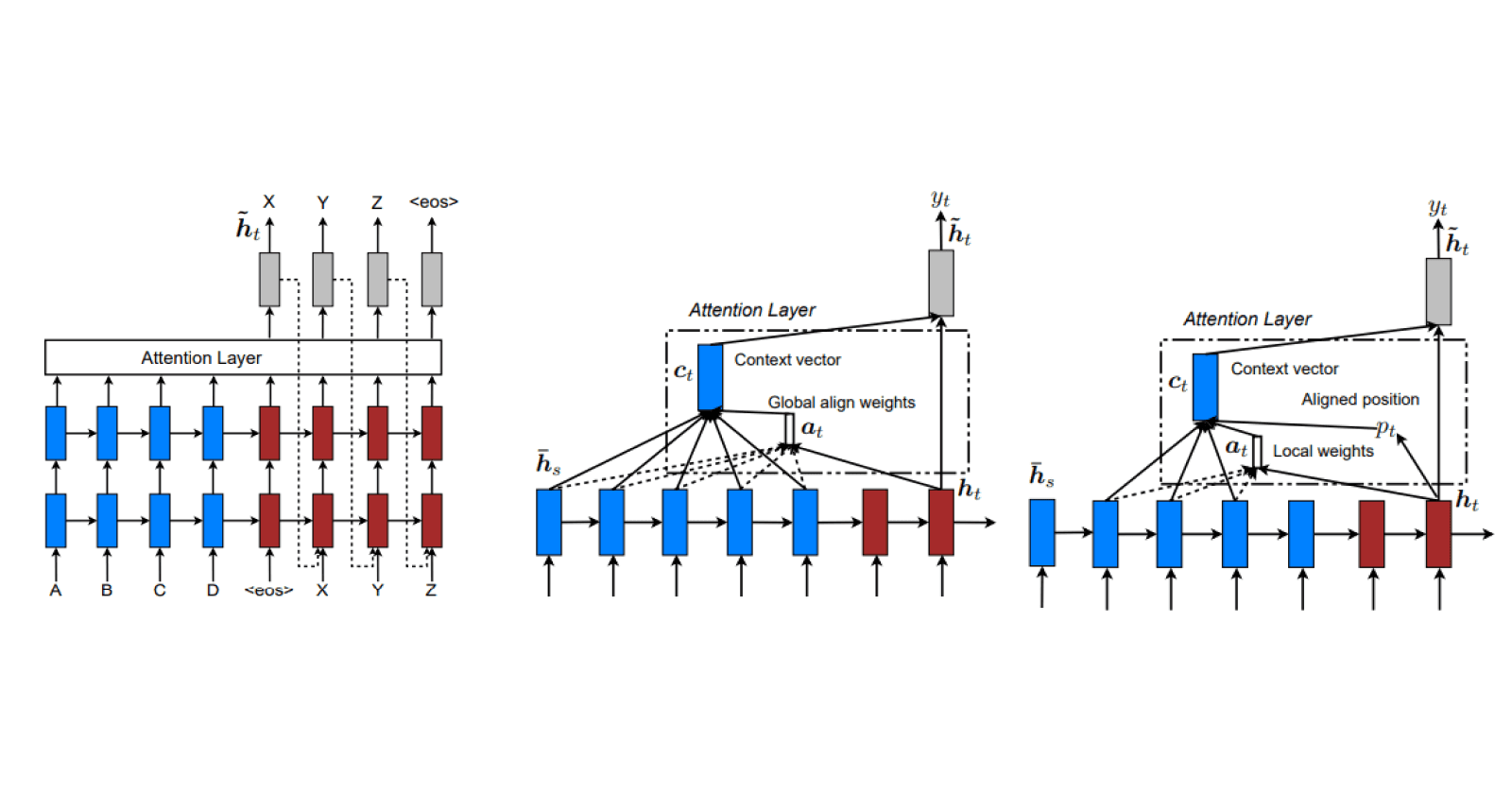
Bahdanau Attention was proposed for Neural Machine Translation task using Bi-directional RNN encoder and RNN decoder.

In each decoding step,
- hidden state of decoder (query) is used to attend to all hidden states of the encoder (keys) to compute attention score for each hidden state
$$\begin{align} h_j &= Concat(\overrightarrow{h_j}, \overleftarrow{h_j}) \\ e_{t,j} &= MLP(s_{t-1}, h_j) \\ \alpha_{t,j} &= \frac{exp(e_{t,j})}{\sum_{k=1}^{T}{exp(e_{t,k})}} \\ \end{align}$$
- context vector is then computed as weighted sum of hidden states of the encoder (values) with attention scores as the weights
$$c_{t} = \sum_{j=1}^{T}\alpha_{t,j}h_j$$
The attended context vector along with the decoder hidden state is then used to predict the next token.
Here is an interesting thread by Andrej Karpathy on how Bahdanau ended up building this attention mechanism.